
European experts came together last week in an icy Paris to review Jisc’s evolving architecture for learning analytics. The event at L’Université Paris Descartes was jointly hosted by Apereo and Jisc. Delegates included representatives from the Universiteit van Amsterdam, the Pädagogische Hochschule Weingarten in Germany, Surfnet in the Netherlands, CETIS and the Lace Project, as well as Jisc and Apereo.

The architecture walkthrough involved participants taking on the following roles for the day:
- Oracle (knows everything about the architecture)
- Student
- Teacher
- Tutor
- Researcher
- Security expert
- Software architect
- Privacy enhanced technologist
- Front end developer
- Federative log on expert
- Enterprise service bus expert
- Data governance expert
- Writer
- Chair
It turned out to be a very effective way of getting some in depth constructive criticism of the model, which Jisc is using to procure the components of a basic learning analytics system.

Consent service
The workshop was organised in conjunction with the Apereo Europe conference and an event the following day around ethics and legal issues. It was interesting how almost immediately the architecture session got caught up in issues relating to privacy. These were of such concern to the Germans present that they believed their students wouldn’t be prepared to use a learning analytics system unless the data was gathered anonymously. Once learners had gained confidence with the system they might be persuaded to opt in to receive better feedback. Thus the consent service was confirmed by the group as a critical part of the architecture.
Two use cases were suggested for the consent service: 1. students control which processes use their data, and 2. the institution wants to use data for a new purpose so needs to obtain consent from the students. I find myself wondering about the logistics here: what happens if the student has left the institution? Will you risk having large gaps in the data which diminish the value of the overall dataset?
One participant suggested that students could decide if they wanted analytics to be temporarily switched off – like opening an incognito window in a browser. This would allow them to have a play and do some exploration without anything being recorded. The logistics of building this into multiple systems though would certainly also be complex – and it would potentially invalidate any educational research that was being undertaken with the data.
Students may be worried about privacy, but handling the concerns of teachers was also felt to be crucial. It was suggested that statistics relating to a class should remain private to the teacher of that class; concern was expressed that learning analytics could be used to identify and subsequently fire ineffective teachers. “Could a predictive model allow unintelligent people to make decisions?” was the way the participant with the “teacher” role summed up the perennial battle for control between faculty and central administators.
One suggestion to minimise privacy infringements was to use the LinkedIn model of notifying you when someone has looked at your profile. Certainly every time someone views a student’s data it could be logged and be subsequently auditable by the student.
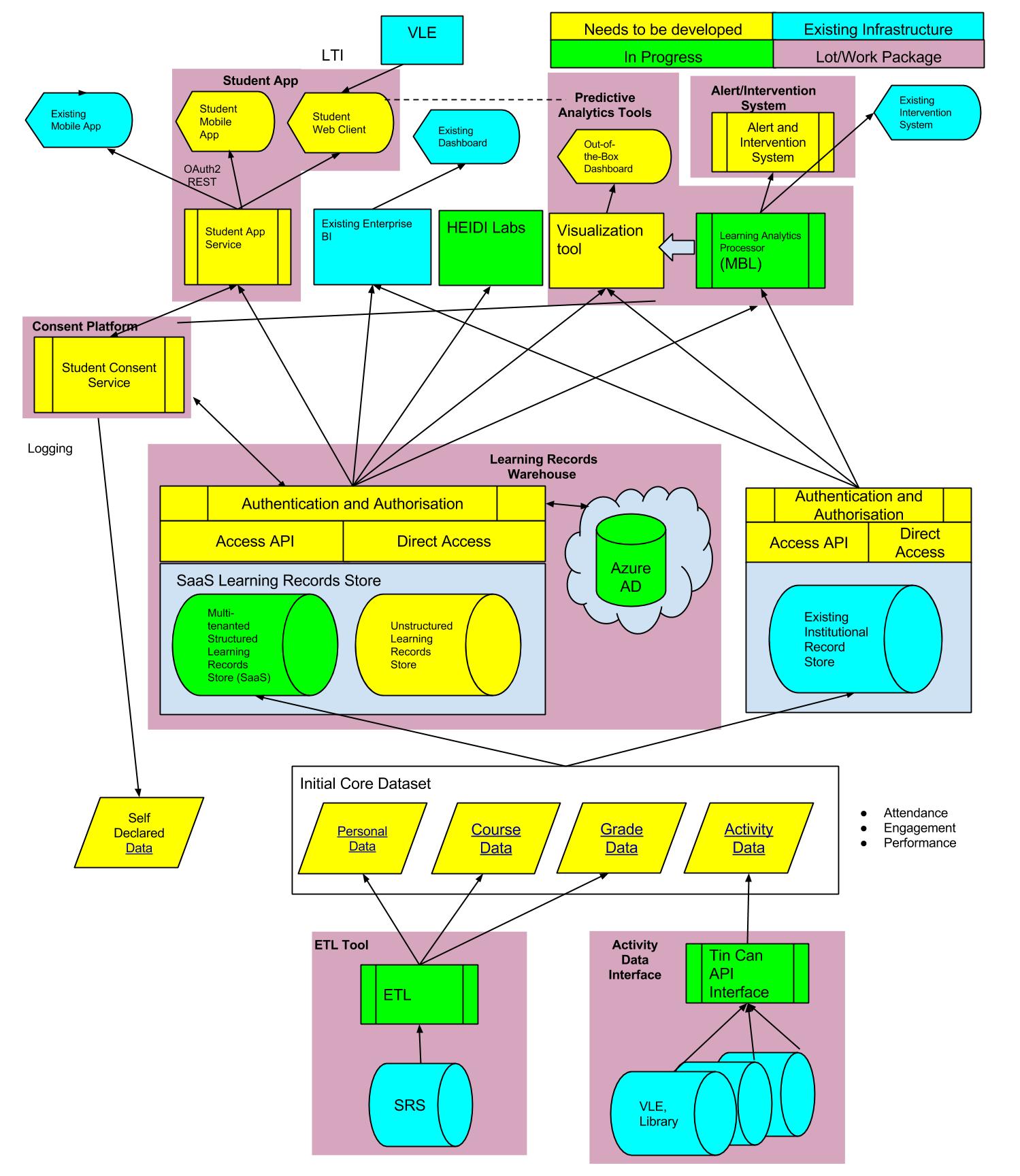
Student app
One idea was for the student app to use an open API, allowing other student-facing services to be integrated with it. Another issue raised was that most analytics is carried out on data sources which can be fairly “old” however there may be a need for realtime learning analytics. And a student app which assessed whether learning outcomes had been achieved could also be very useful.
One of the most interesting ideas mooted was this: could the most important source for predictive analytics be “self-declared” data? It might be that some wearable technology monitoring your sleep patterns or your exercise levels for example could be mapped onto your learning performance. Or you might want to log the fact that you’d watched several relevant youTube videos that you’d discovered.
Learning record store
Concern was expressed around the performance of dashboards when required to process big data. Thus the ETL (extract, transform and load) layer is crucial to determine what data is stored in the learning records warehouse.
Alert and intervention system
This should not only be in place to help those at risk but should also allow the teacher to analyse how well things are going on overall in the class. Interventions might be to congratulate students on their progress as well as to address potential failure or drop-out.
Learning analytics processor
This was deemed to be so critical that it should form a separate layer, underpinning the other applications. Meanwhile compliance with the Predictive Modelling Markup Language has already been specified by Jisc as a requirement for the predictive models to be used by the learning analytics processor. But one member advised us to be wary of “gold-plated pigs” – some vendors are great at presenting beautiful apps and dashboards which may have shaky underlying models and algorithms doing the predictions. Most staff are unlikely to want to know the fine detail of how the predictions are made but they will want to be reassured that the models have been checked and verified by experts.
Standards
The use of technical, preferably open, standards is going to be important for an architecture comprising a number of interchangeable components potentially built by different vendors. The Experience API (Tin Can) has been selected as the primary format for learning records at the moment; it should be relatively easy to convert data from the LMS/VLE to this format, and some plugins e.g. Leo for Moodle already exist. However there may be a maintenance overhead every time each LMS is upgraded.
It was suggested that the IMS Learning Information Services (LIS) specification would be appropriate for storing data such as groupings of individuals in relation to courses. There is already reportedly a LIS conversion service for Moodle.
The problem of ensuring universally unique identifiers for individuals (and activities) was also noted.
Security
Our “cracker” (security expert) was concerned that security issues will be complex because of the number of different systems in place. Meanwhile there’ll be ongoing requirements for patches and version updates for the different LMSs and student information systems.

Conclusions
We were reassured that the architecture, with some minor changes suggested by the group, is robust, and we’ll be aiming to put in place a basic “freemium” learning analytics solution for UK universities and colleges by September.
We hope also that this will contribute to international efforts to develop an open learning analytics architecture and we look forward to working with other organisations to develop it further in the future.
I’m grateful to all the participants who made such useful contributions on the day and in particular to Alan Berg of Apereo and the University of Amsterdam for initiating this workshop and doing the lion’s share of the organisation.